
原文标题:Large Language Model Supply Chain: A Research Agenda
原文作者:王申奥,赵彦杰,侯心怡,王浩宇(通讯作者)
作者单位:华中科技大学Security PRIDE团队(Security, Privacy, and Dependability in Emerging Software Systems)
原文地址:https://arxiv.org/pdf/2404.12736 已被CCF-A类期刊TOSEM接收
通讯作者主页:https://howiepku.github.io/
LLM Supply Chain推荐阅读列表:https://github.com/ShenaoW/awesome-llm-supply-chain-security
TL;DR
大语言模型(LLMs)已经对自然语言生成、代码生成等领域产生了重大影响。随着Agent应用范式的快速发展,将LLMs集成进现实世界应用从而完成各种复杂任务也逐渐成为可能。然而,LLM应用的开发不仅仅是简单的模型部署或者接口调用,而是涉及到开发,部署和维护过程中的一系列第三方组件、框架和工具链。这种复杂的供应链关系导致LLM系统软件容易受到一系列漏洞的影响,从而损害训练数据、模型或者部署平台的完整性与可用性。本文首次提出了对LLM供应链的明确定义,并且从软件工程(SE)和安全与隐私(S&P)的两个视角来回顾供应链各个阶段的现状,并确定目前的挑战与未来的研究机会,以期为该领域提供有益的见解和启示。
1. 研究背景
将LLMs集成到现实世界应用中需要一系列开发和部署工具链,如数据处理(如用于数据质量保证的Cleanlab和用于数据管理的Hugging Face Datasets)、模型训练(如用于分布式训练的PyTorch Distributed)、优化(例如,用于模型量化的 OmniQuant和用于模型合并的 MergeKit)和部署(例如,用于Agent工作流编排的AutoGPT和用于检索增强生成的RAGFlow)。这些工具链的引入导致LLM应用开发、部署和维护的各个阶段都面临供应链风险,OWASP已经将供应链漏洞列入LLM应用十大安全威胁之一。然而,以往的研究尚未对LLM供应链进行明确的定义,其中所面临的挑战和未来的研究路线也不明确。
2. LLM供应链定义
本文首先提供了LLM供应链的明确定义,包括三个层级,分别是:基础设施层,基础模型层以及下游应用生态。整个供应链涉及到的参与者包括上游数据提供商、模型开发社区、模型存储库、分发平台和应用市场,以及模型开发、分发和部署过程中的研究人员、工程师、维护人员和最终用户。
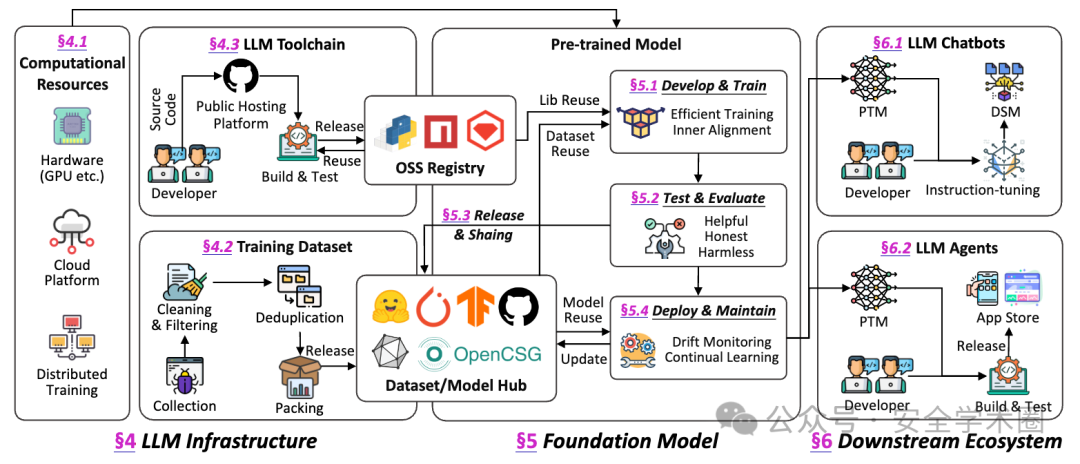
基础设施层:包括计算资源,数据集和开发工具链。计算资源包括模型训练和部署过程中所涉及的硬件资源,云服务,以及分布式系统。数据集包括大规模文本语料库(包括自然语言和代码)、专业领域数据集和多模态数据集。LLM工具链包括模型训练到部署的整个生命周期中所涉及的工具、第三方组件和框架。
基础模型层:以LLM开发生命周期的各个阶段划分,包括预训练、微调、测试、发布、共享、部署和维护。其中,模型发布和共享尤为关键,各种预训练模型的重用构成了模型依赖关系的基础。
下游应用层:主要是基于LLM的下游应用程序,例如聊天机器人、自主代理和特定领域的LLM解决方案。上游的工具链漏洞或者模型缺陷会通过供应链传递到下游应用中。
在LLM供应链中,存在多层级的依赖关系,简要介绍两种:一是继承自传统开源软件供应链的工具依赖,即开发工具链之间的依赖导致漏洞传播。例如,ShadowRay[1](CVE-2023-48022)漏洞导致数千台公开暴露的Ray服务器受到损害,受感染的GPU集群可能会被利用并部署挖矿软件。其次是来自于预训练模型和数据集复用的依赖关系。开发者通过模型/数据集共享平台(例如Hugging Face)来实现预训练模型/数据集重用,由此产生的模型/数据集依赖也会导致安全风险传播。近期的相关研究揭示了针对预训练模型/数据集的恶意代码投毒攻击实例[2],可能造成下游用户在加载模型/数据集是导致恶意代码执行。此外,模型或数据集中的偏见,毒性内容,幻觉,甚至后门也会随着模型/数据集依赖传播到下游模型乃至应用中,由于模型本身的黑盒特性,静态检测很难保证模型安全性。
3. 研究路线图
基于上述定义与分析,本文从软件工程和安全的视角来分析LLM供应链的现状,确定其中存在的关键挑战并且制定未来的研究路线。
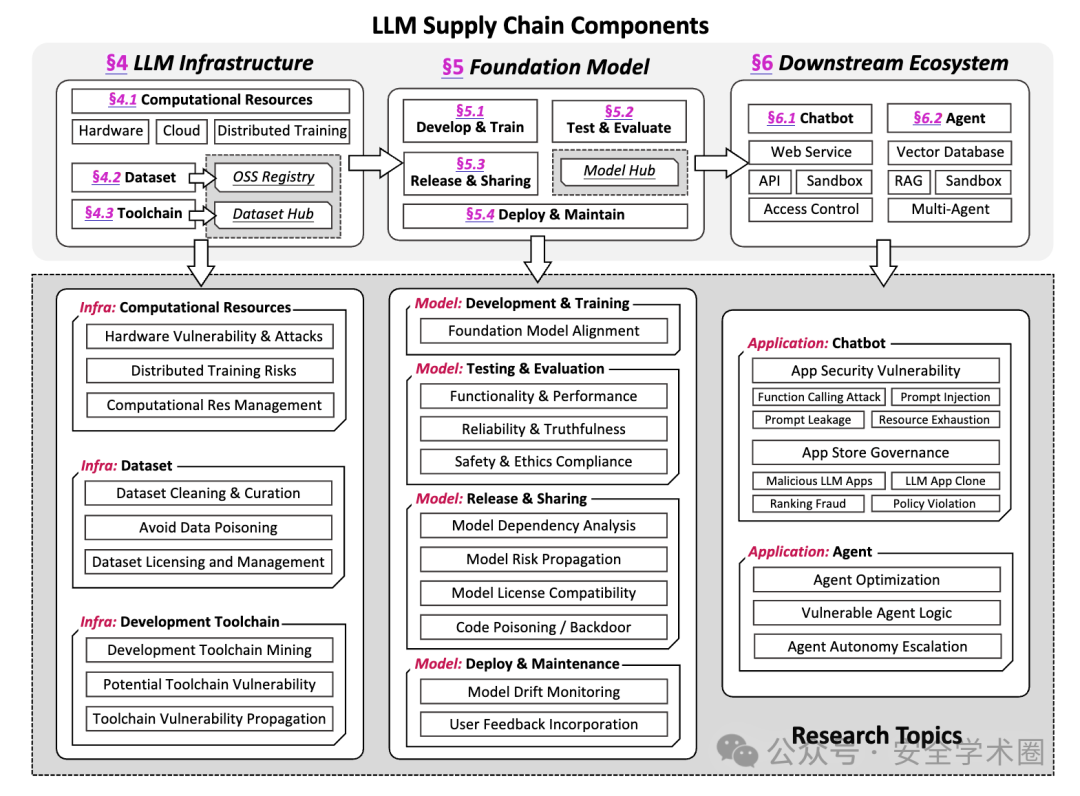
3.1. 基础设施层
基础设施层所面临的挑战与快速发展的LLM生态密切相关,计算资源、数据集、工具链,任一环节的安全问题都可能传播到下游模型训练和应用开发过程中,造成严重的安全影响。
计算资源:硬件供应商单一过度依赖引发了潜在的供应链脆弱性,一些硬件级漏洞在LLM供应链中可能产生严重的安全后果。随着模型趋向更大更复杂,分布式系统和专有AI云服务已被广泛采用,但也引入了新的攻击面。最近,PyTorch的分布式RPC系统中发现了一个关键漏洞(CVE-2024-5480)。由于输入验证不足,可能允许当工作节点序列化并发送Python自定义函数(UDFs)到另一个节点时执行远程代码。
数据集:目前LLM供应链中的数据集具有前所未有的规模和多样性,并且对数据质量、偏见和隐私的关注日益增加。在代码大模型领域,开源仓库中的代码已成为训练数据的关键来源,这对代码质量、开源许可证和代码中潜在的安全漏洞都提出了更高的要求。此外,数据集管理组件中也可能存在潜在的安全漏洞,在数据集准备和模型训练工作流程中需要实施更严格的安全实践。
工具链:LLM的开发工具链包括许多新兴的第三方库、框架和专有工具。像Hugging Face的Transformers库可能在LLM供应链中引入系统性漏洞, PyTorch和TensorFlow等传统AI框架也常常会存在安全问题。例如,TensorFlow的Keras框架中Lambda Layer存在漏洞(CVE-2024-3660),允许任意代码注入,而PyTorch使用Pickle进行模型序列化也引入了潜在的反序列化漏洞。此外,针对LLM开发、部署和维护有许多新兴的开源框架或工具发布。LLM开发工具链的日益复杂,加上该领域的快速迭代,给整个LLM开发、部署和维护流程中的安全实践带来了巨大挑战。
3.2. 基础模型层
基础模型层主要关注于LLM训练,测试,发布和部署的相关内容。关于模型训练和测试部分,相关研究十分普遍,包括模型对齐,性能测试,可靠性测试(幻觉,事实一致性),安全性测试(提示注入,越狱攻击),道德和无害性测试(隐私,偏见等)。本文仅对模型内容安全方面的相关挑战进行了概述,重点关注于模型共享和发布阶段,强调模型复用衍生的一系列供应链角度的研究问题。
模型共享:在LLM供应链中,模型发布和共享构成了模型间复用与依赖的核心。像Hugging Face这样的平台目前已经托管了超过110万模型和24万数据集(截止11月22日),显著提高了模型和数据集开发过程中的协作性和可重用性。然而,供应链风险管理仍然是一个关键挑战,特别是在模型来源和安全保证方面。模型卡片和相关文档,往往无法准确反映模型的真实性质和能力。这种脆弱的模型来源验证使生态系统容易受到恶意模型投毒和其他形式的篡改。通过微调、模型合并等技术重用模型引入了复杂的模型依赖关系,可能导致风险传播。然而,当前的开源模型生态系统缺乏对这些相互依赖关系进行建模。模型本质上被视为黑盒,易受攻击的预训练模型可能隐藏着偏见、后门或其他恶意特征。除此之外,LLM的开源许可管理仍然是一个争议性问题,例如,围绕像Llama3这样的模型的许可条款对模型命名提出了严格要求,可能会出现一些许可合规性问题。此外,模型托管平台本身的安全性也值得关注。像Hugging Face平台上托管的模型转换工具这样的服务已被证明容易受到操纵[3],可能允许恶意代码被引入到LLM中。
3.3. 下游应用生态
下游应用生态直接面向用户交互,各种潜在的缺陷和安全问题都会直接暴露并且影响用户体验。目前,将LLM集成到现实世界应用中有各种各样的形式,我们主要以LLM对话系统和Agent代理来展开介绍。
LLM对话系统:由LLM驱动的对话系统和应用代表了LLM供应链下游生态的典型范式。这些应用利用LLM的能力,为不同领域提供交互式的智能解决方案。像GPT Store这样的平台正在成为集中枢纽,开发者可以在此发布他们的LLM应用(即GPTs),用户可以访问并使用这些工具来完成特定的任务和目标。这个生态系统与移动应用商店类似,旨在为LLM应用创建一个安全和用户友好的环境。LLM应用的普及降低了开发者准入门槛。然而,这种快速的增长和可访问性也引入了新的漏洞和治理挑战。随着这些平台的发展,它们必须应对LLM应用特有的新型安全威胁[4],如提示注入攻击和高级功能如函数调用的潜在误用。此外,LLM应用的独特性质,即能够实时生成和操纵内容,也对质量控制、伦理考量和法规遵从提出了前所未有的挑战。
LLM代理:LLM驱动的自主代理(ALAs)能够提供跨多个领域的自主或半自主任务执行。这些代理利用LLM的高级推理和知识合成能力来执行复杂任务,做出决策,并以复杂的方式与用户和系统互动。复杂的ALAs架构将LLM与外部工具、知识库和决策框架相结合。这些代理越来越能够以最小的人工干预执行复杂、多步骤的任务。例如,在软件开发领域,ALAs被用于代码生成、调试,甚至系统设计。然而,随着这些进展,关于越来越多的关于ALAs的伦理影响和潜在风险的担忧也在增长。一方面的安全挑战是存在易受攻击的代理逻辑。ALAs依赖于非确定性结果,验证代理行为是从逻辑上可能是不全面的,对手可以识别并利用代理逻辑中的漏洞来实现恶意结果。另一方面,基于LLM的代理可能会获得未预期的控制或决策能力水平,可能导致有害或未经授权的行为,对系统完整性、数据安全和用户安全构成风险。
4. 结论
LLMs的强大的生成能力和集成到下游Agent中完成现实世界任务复杂任务的潜力,使得围绕LLMs的系统软件生态日益繁荣。该生态中的各种开源制品(包括预训练模型、数据集、提示词和工具链)的复用和交互产生了一系列复杂的依赖关系,共同构成了LLM供应链。目前,围绕LLM供应链的相关研究尚处于起步阶段,缺乏系统的方向性指导。因此,本文提出了第一个全面的LLM供应链研究议程,通过对LLM供应链的组成成分和依赖关系进行定义,总结并回顾LLM供应链各部分的研究现状。在此基础上,本文通过软件工程和安全的双重视角对LLM供应链进行系统性分析,确定了LLM生态快速发展所带来的复杂挑战和研究机遇,并拟定了一个初步的研究议程,旨在为该领域未来的研究提供宝贵见解。
参考资料
ShadowRay漏洞: https://www.oligo.security/blog/shadowray-attack-ai-workloads-actively-exploited-in-the-wild
[2]Models Are Codes: Towards Measuring Malicious Code Poisoning Attacks on Pre-trained Model Hubs.: https://arxiv.org/pdf/2409.09368
[3]Hijacking Safetensors Conversion on Hugging Face.: https://hiddenlayer.com/innovation-hub/silent-sabotage/
[4]On the (In)Security of LLM App Stores: https://arxiv.org/pdf/2407.08422
安全学术圈招募队友-ing
有兴趣加入学术圈的请联系 secdr#qq.com